
The phrase “bad for SEO” describes unethical and outdated SEO practices. Indeed, PDFs have not reached that point. They are one of the most popular document extensions on the web.
So, let’s rephrase the question and ask:
Is creating PDFs detrimental to your search engine optimization efforts?
And…
Are you more likely to hurt your SEO efforts by publishing a PDF instead of placing the content on a normal webpage?
That’s today’s focus. We’ll learn about what makes PDFs detrimental for SEO and the best ways to optimize them.
But first, here is a quick rundown of PDFs:
What Are PDFs?
The term PDF stands for “Portable Document Format”.
Adobe Systems invented the format in the early 1990s and released Version 1.0 of Adobe Acrobat in June 1993.
Leonard Rosenthol, the format’s architect, sought a way to exchange information across systems, users, and machines in a way that the file looked the same everywhere it went.
In the early 1990s, computer users had to contend with compatibility and rendering issues. It was a pain to print documents that needed to be reproduced without any deviations, such as tax filing forms.
PDFs grew in popularity during the next decade, as they preserved the formatting with no change when viewed across different devices or programs. Shared documents could be printed with a high level of consistency.
Even today, if you attempt to print a document, you always get an option to print it as a PDF.
Fast forward to the age of search engines, and PDFs have remained relevant.
Google identifies results with PDFs using a special tag.
You can get a rich result snippet featuring information contained in PDF to answer your query.
Many of the benefits that made PDFs popular, such as restricted formatting, have worked against the document format in the present day.
Does Google Crawl PDFs?
Yes, search engines, including Google and Bing, index PDFs.
Google started indexing PDFs in 2001, and its collection has grown to millions of files.
When Google crawls the web, it converts PDF and other similar documents to HTML versions. John Mueller confirmed this in his tweet back in August 2018:
FWIW we convert PDFs & other similar document types into HTML for indexing too, so theoretically there wouldn’t be too much difference.
—
John
Many people have also wondered:
Does Google have the ability to crawl scanned documents or image-based PDFs?
Yes, Google utilizes its Optical Character Recognition (OCR) technology to recognize and convert text from non-searchable PDFs.
There are certain instances when Google cannot crawl a PDF file. For instance, if it’s password-protected or encrypted.
You can also exempt URLs containing the PDF from being indexed (more on this later).
Are PDFs Bad for SEO?
Many reasons have been given for why PDFs are bad for SEO. Let’s briefly touch on them:
1. PDFs take second precedence to normal pages
Here is the biggest reason marketers are against PDFs:
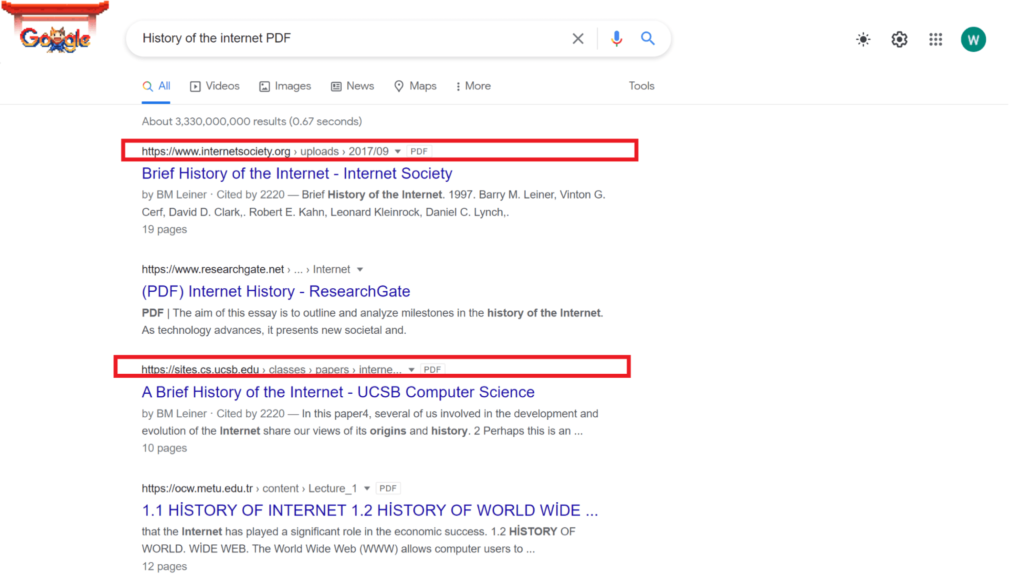
If we search for “Effective guide to SEO”, the first ten results redirect to website pages.
There is no PDF insight.
Wait, I have spotted some…
There are two PDF results occupying positions 33 & 34. And the PDFs are actually more detailed than many of the pages outperforming them in ranking.
It’s only after amending the search phrase to “Effective guide to SEO filetype: PDF” that PDF results crop up on the first page.
Because PDFs are often more detailed, some users may add the PDF to their queries to return more results with PDF files.
2. PDFs are not mobile-friendly
If you have had the unlucky chance to interact with a PDF on a mobile screen, you may have been left tilting the screen to landscape mode or zooming in & out constantly.
3. PDFs are not easily formatted or updated
Once you create a PDF file, you may need access to the original document to make changes.
While you may try to export the PDFs to a word document, the results are not always perfect and some of the formatting may be lost.
Compared to updating a normal page, there are more steps such as uploading.
4. Users can’t easily navigate to other website pages
When someone visits your website, they can easily navigate to your pricing or blog pages. You can even drive conversions this way.
Users often view the PDF file through the browser’s PDF viewer. Some people will use offline programs.
In both cases, navigating back to your website will require additional steps.
5. Large PDFs may waste the crawl budget
Google allocates a crawl budget to each website. It determines the possible number of web pages Google may crawl during a given time frame.
It’s held that since some PDFs can be large files, they may consume more of the crawl budget, thus impacting how other pages are crawled.
6. PDFs are not frequently recrawled
Google understands that PDFs are not frequently updated. So, they don’t recrawl the files as often as HTML pages.
7. PDFs don’t support structured data
You can’t markup the page with structured data to help search engines understand elements such as recipes.
8. PDFs have a limited number of link types
Additionally, you don’t have access to no-follow links or sponsored links.
9. PDF images may not easily make it to image search results
Images contained in PDFs may not be readily displayed in image search results unless they are uploaded separately to a HTML page.
For instance, ResearchGate takes this approach:
The figure appears in the image results, but here, it’s added separately.
10. It’s harder to track engagement metrics with a PDF
Tracking engagement metrics for PDFs is a lot harder than for HTML pages. The metrics are often useful when performing SEO optimization.
For instance, you don’t have access to heatmaps to check how users interact with the documents. You may not know if they read to the end of the page.
11. A PDF may result in duplicate content:
Some blogs generate PDF versions of their posts without implementing proper URL canonization.
While Google is clear that they don’t penalize sites for duplication, it may pose other issues, such as backlink dilution.
12. It’s harder to properly markup a PDF
Many PDF creations or export tools don’t provide you with the option to define other document properties such as the title, metadata, or keywords.
How to Make a PDF SEO-Friendly?
Despite the seemingly many problems with PDFs, it’s not entirely possible to ditch them altogether. The alternative is to make them more friendly to search engines with these tips:
1. Create high-quality content
The advice here is quite simple and routine.
Your PDF should have high-quality content that is unique and offers more value to readers.
As long as you build great content, Google will index your PDFs, and you may have a shot at appearing in SERP results.
2. Convert poor-performing PDFs to normal HTML pages
There are certainly many advantages of converting an already existing PDF into an HTML page.
But how do you know which PDFs to convert to normal HTML pages?
| Should I convert? | Verdict |
| The PDF has many backlinks and generates good traffic | Don’t convert |
| The information is less accessible as a PDF | Convert |
| The PDF has exhibited poor performance with few backlinks and low traffic | Convert |
After making the transition, it’s essential to use a 301 redirect to show the search engine that it should gradually give more attention to the new URL.
For the newly converted HTML page to perform well, you must consider all the best optimization techniques, such as ensuring that the page is optimized for search intent.
3. Give precedence to HTML pages through canonicalization
Many blogs may create PDF versions of their content.
Now, when Google encounters the PDF and HTML pages, it considers the two pages as duplicates.
The crawler will choose one page as the canonical version. It will be crawled more often. Sometimes, it may give both pages equal weight.
So, if there are any occurrences of content duplication, it’s better to give precedence to the HTML page as it may perform better.
There are various ways to specify the canonical page, including:
- Adding rel=canonical tag (Only works for HTML pages)
- Sending a rel=canonical HTTP header (Suitable for PDFs)
- Using sitemaps
Dive deeper: Check out the recommended ways to consolidate duplicate URLs.
4. Create a landing page for PDFs
It’s not always feasible to convert an existing PDF file into an HTML page. Sometimes the file may be too long or contain lots of visual content.
In that case, consider creating a landing page. You can even use it to generate subscriptions to your email newsletter.
You can similarly publish a blog post summary with a link to the longer PDF version.
5. Modify the Title & Metadata attributes
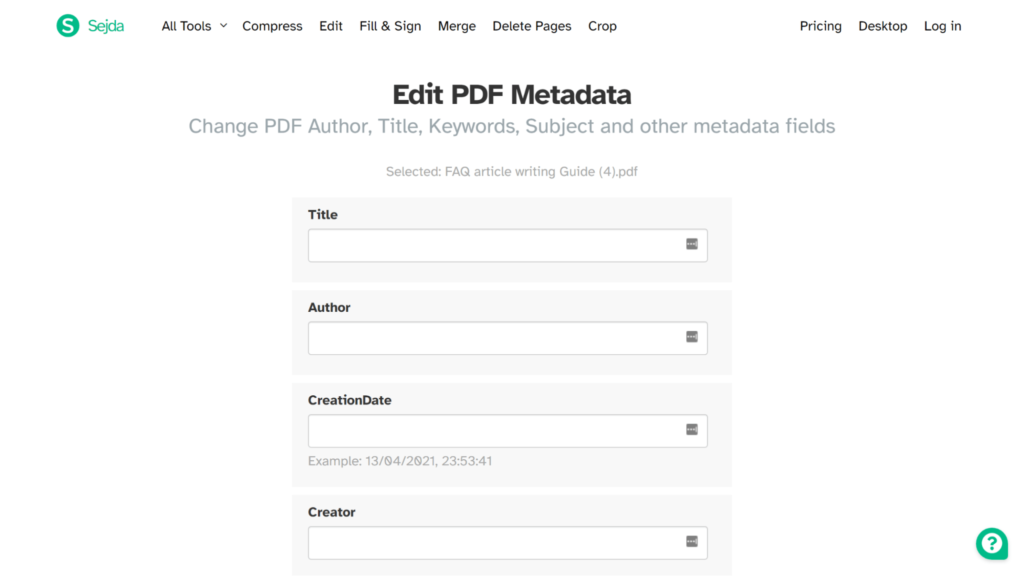
You don’t need a paid tool such as Adobe Acrobat to modify a PDF’s properties. Some online tools provide this functionality for free, for instance, Sejda.
- Go to https://www.sejda.com/edit-pdf-metadata
- Upload your PDF document
- Make changes to the document properties, e.g. Author, Title, Subject
Similarly, don’t overlook the filename….
….make it descriptive.
The URL structure should be readable:
Incorrect: https://example.com/wp-content/uploads/2019/11/SAYS.pdf
Correct: https://example.com/how-to-make-friends.pdf
6. Ensure the headlines are properly formatted and add alt-text to images
Before converting your documents to PDF, take time to label all the headings, from H1 to H6, as you deem appropriate.
You can also add alt descriptions to the images used in the PDF.
First and foremost, it improves the accessibility of PDF to visually impaired users. That’s because the screen reader announces the alt-text for each image.
Search engines may also rely on the alt-description to understand visual content.
7. Link to and from the PDF document
You can include internal links and external links in the PDF document. Google can follow the links and pass on SEO juice to linked pages.
If you have a highly linked PDF, don’t miss out on leveraging this easy opportunity to improve your other pages.
8. Use a searchable text-based PDF
Ensure that you have created a text-based PDF. If you can copy and paste the text, then Google can do it too without relying on its OCR algorithms.
9. Use formatting that makes the PDFs easily readable on mobile devices
Try to go the extra step and create mobile-friendly PDFs.
As online publishers, we wrongly assume that everyone will be using a desktop device to access the content just because we used a computer to publish it.
10. Start tracking metrics about the performance of PDFs
You should closely track your PDFs’ performance and use the insights to make the best decisions about your content strategy. Learn how to implement event measurement on Google Analytics.
How to Stop Google from Indexing a PDF?
There are times when you want to make the PDF inaccessible to crawlers. At the same time, you may not want to encrypt or protect it with a password to ensure that everyone can easily access it.
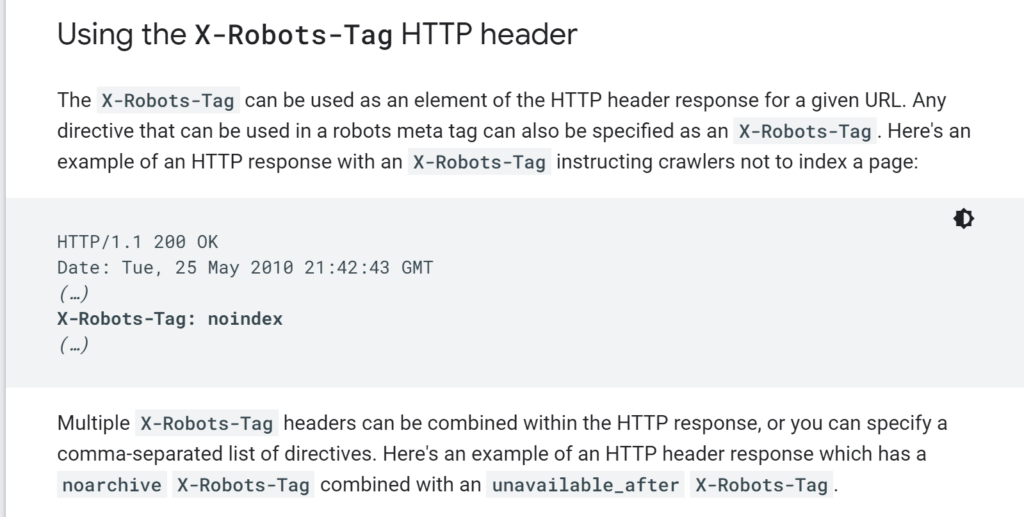
You can stop Google from indexing the PDF file by adding an X-Robots-Tag as an element to the HTTP header that serves the PDF.
Bottom Line
PDFs are highly relevant, and many websites still publish them. The foremost reason is that they offer a way to share long-form content in a book or report format.
Users can download the PDF files and read at their own pace without having to revisit the website.
While all this is good news, if possible, use HTML pages in place of PDFs. And if you have to use PDFs to share certain content, follow all the recommended PDF optimization techniques.



